Quick answer: The Axios npm supply chain compromise is not just a package security story. It becomes an operations story the moment your team has to answer where the compromised dependency is running, what changed in production, and which systems need action first.
TL;DR
- The Axios compromise is a timely example of how software supply chain attacks turn into high-pressure incident investigations.
- The first challenge is rarely finding more alerts. It is building context fast enough to act.
- Strong response depends on quickly mapping affected services, deploy history, dependency exposure, and suspicious runtime behavior.
- OpsRabbit is built for that time-to-context gap.
What Problem Are We Solving?
When a dependency compromise hits a widely used package, most teams do not struggle with awareness for very long. Security news travels fast.
What slows them down is the next set of questions:
- Which production services import the affected package?
- Which versions are deployed right now?
- What changed in the last release window?
- Are any services showing abnormal outbound traffic, failed calls, or new errors?
- Which incidents or alerts are actually connected, and which are noise?
That is where dependency incidents become operationally expensive.
Short Answer
The right response is to treat a dependency compromise like a live cross-functional investigation, not just a package upgrade task. Teams need exposure mapping, service ownership, recent change history, runtime symptoms, and prioritized remediation in one place.
Why the Axios story matters right now
Microsoft Security recently highlighted a supply chain compromise involving newly published Axios npm package versions and linked the activity to a state-sponsored threat actor. That matters because Axios is recognizable, broadly used, and likely embedded in places teams forget to check until an incident starts.
This is what makes supply chain incidents dangerous for operations teams:
- One dependency can touch many services. Frontend apps, APIs, workers, internal tooling, and automation jobs may all rely on the same library.
- The blast radius is not obvious from the alert alone. Security advisories tell you what happened, but not where it is running in your environment.
- Incident pressure compresses decision time. Teams need fast answers on exposure, containment, and remediation while executives and customers ask for status.
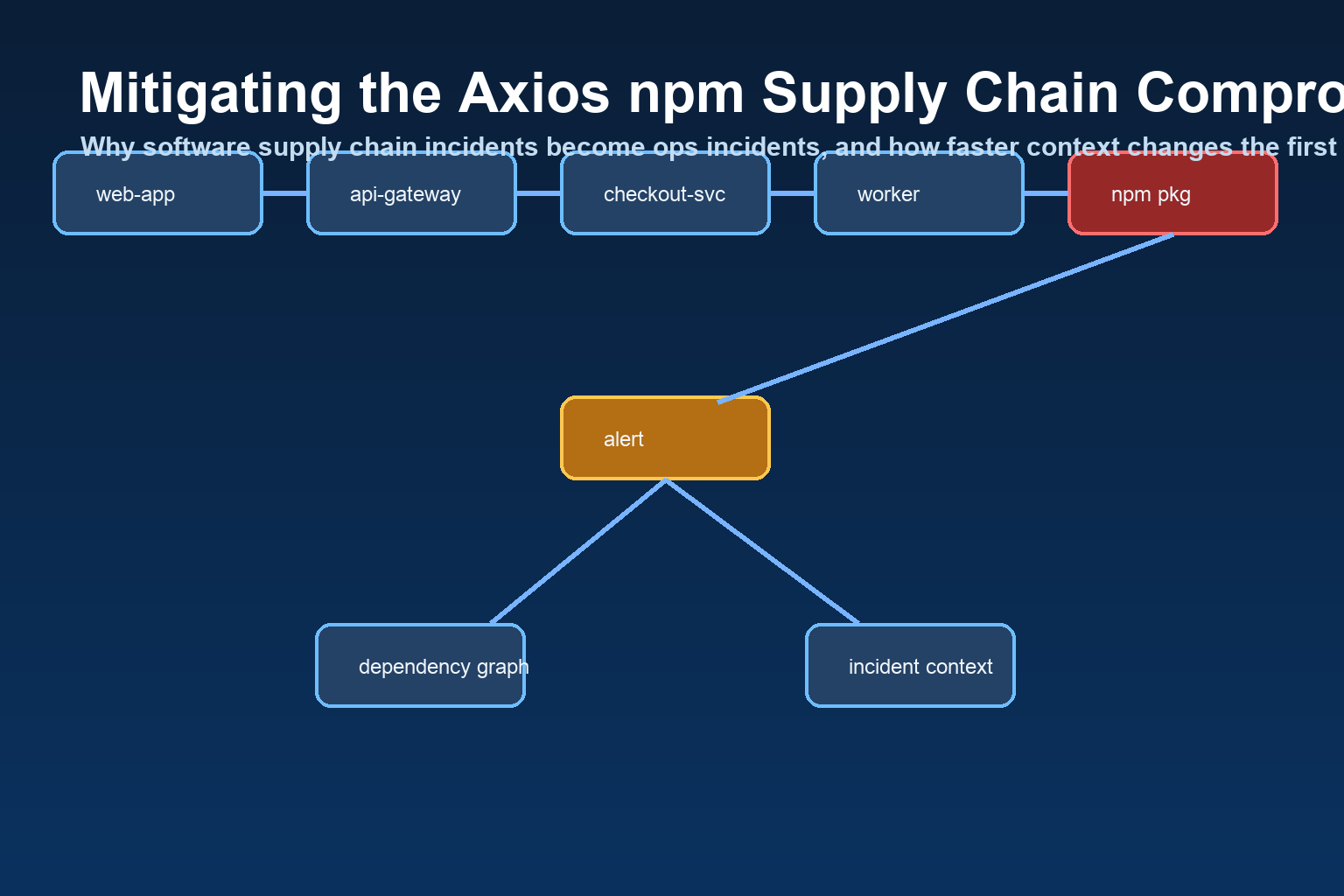
The real bottleneck in dependency incidents is usually context building, not awareness.
What responders should do in the first hour
A practical first-hour playbook looks like this.
1. Identify every place Axios exists
Start by locating the package across repositories, lockfiles, container images, artifact manifests, and deployed services. The goal is not just to confirm whether Axios exists somewhere. The goal is to know which running systems might be affected.
2. Correlate exposure to recent deploys
A vulnerable version in source control is one thing. A recently deployed compromised version in production is another. Tie dependency findings to release events, change windows, and service ownership.
3. Look for runtime signals that change the priority
If a dependency compromise can trigger outbound calls or malicious downloads, check network egress, DNS lookups, unusual process behavior, and service-to-service anomalies. This helps separate theoretical exposure from active risk.
4. Triage by business criticality
Not every affected service deserves the same urgency. Customer-facing auth, payments, and core APIs should move to the front of the queue. Internal tools may follow after containment of higher-risk systems.
5. Build a working incident narrative
Responders need a shared answer to basic questions: what happened, what is exposed, what evidence supports it, what is contained, and what is next. Without that narrative, teams lose time in chat and status meetings instead of remediation.
Why this is still painful in most environments
Most teams already have scanners, alerts, observability tools, cloud logs, and ticketing systems.
The problem is that the evidence lives in different places.
Security can tell you the package name. Observability can tell you where errors are rising. CI can tell you what deployed. Cloud telemetry can hint at suspicious egress. Slack can show who is responding.
But responders still have to connect those threads manually.
That manual stitching is where time-to-context explodes.
Where OpsRabbit fits
OpsRabbit is designed for exactly this part of the workflow.
Instead of asking responders to hunt through multiple systems during a live incident, OpsRabbit helps assemble a usable investigation context fast:
- impacted services and likely owners
- recent deploys and dependency-related changes
- correlated alerts, logs, and operational symptoms
- evidence that supports the most likely incident narrative
- next actions the responder should verify or execute
That matters in supply chain incidents because the investigation window is noisy and expensive. The team that can move from alert to confident scope fastest usually contains the problem with less chaos.
A better framing for dependency incidents
The lesson from the Axios compromise is bigger than Axios.
Software supply chain incidents are no longer just AppSec events. They are operations events, communications events, and prioritization events.
The winning capability is not merely detection.
It is the ability to answer, quickly and credibly:
- where are we exposed
- what is running now
- what evidence changes our urgency
- what should we remediate first
Final thought
Security advisories create awareness. Response quality comes from context.
If your current workflow still requires responders to manually piece together dependency exposure, deploy history, runtime anomalies, and ownership during a live incident, that is the gap to fix.
OpsRabbit exists to close that gap.
If your team wants faster, evidence-backed investigation for dependency and production incidents, it is a good time to pilot OpsRabbit.
FAQs
Why is the Axios npm compromise an ops problem?
Because responders must quickly identify affected services, correlate recent deploys and runtime behavior, and decide what to remediate first across production systems.
What should teams do first after learning about a dependency compromise?
Identify exposure, verify deployed versions, review recent changes and outbound behavior, contain risky workloads, and coordinate remediation with evidence.
Sources
- Microsoft Security Blog - source for current security coverage and Axios compromise mention, accessed April 14, 2026.
- CISA Cybersecurity Alerts & Advisories - guidance framing for high-priority cyber threat response, accessed April 14, 2026.
Last Updated
2026-04-14
Ready to Transform Your Operations?
Ask for a demo today. Experience how OpsRabbit can reduce your MTTR by up to 90%.