OpsRabbit Blog
Insights on IT Operations, AI, and the future of incident management. Stay ahead of the curve with expert analysis and practical guides.
Featured Articles

What AIOps Means in Practice: Use Cases, Expectations, and Where OpsRabbit Fits
AIOps means different things to different teams: alert noise reduction, root cause analysis, self-healing, DevOps acceleration, service intelligence, and executive reliability. This guide maps those expectations to practical OpsRabbit workflows.

Agentic Runbooks for IT Operations: How to Cut Investigation Time Without Automating Blindly
Agentic runbooks help IT operations teams gather evidence, validate context, and recommend the next step faster, without turning incident response into a black-box automation gamble.
When MCP Endpoints Become an Ops Incident: What Teams Should Do After the nginx-ui Takeover Flaw
The nginx-ui takeover flaw is a good reminder that MCP and admin-plane integrations are now part of the incident surface. Here is how ops teams can scope exposure, check for config tampering, and respond faster with context.
Mitigating the Axios npm Supply Chain Compromise Before It Becomes a 2 A.M. Incident
The Axios npm supply chain compromise is a sharp reminder that dependency incidents become operations incidents fast. Here is how teams can investigate impact, reduce time-to-context, and respond with less chaos.

Why AI-Generated Code Is Creating a New Incident Response Problem
AI coding tools are speeding up software delivery, but they are also creating a new investigation burden for operations teams. The real problem is not just more change, it is slower time-to-context when production breaks.

MTTD, MTTF, MTBF, and MTTR: How OpsRabbit Improves the Metrics That Matter for DevOps
A practical guide to four core reliability metrics—and how AI-driven incident investigation with OpsRabbit helps teams detect faster, resolve sooner, and build a clearer picture of system health.
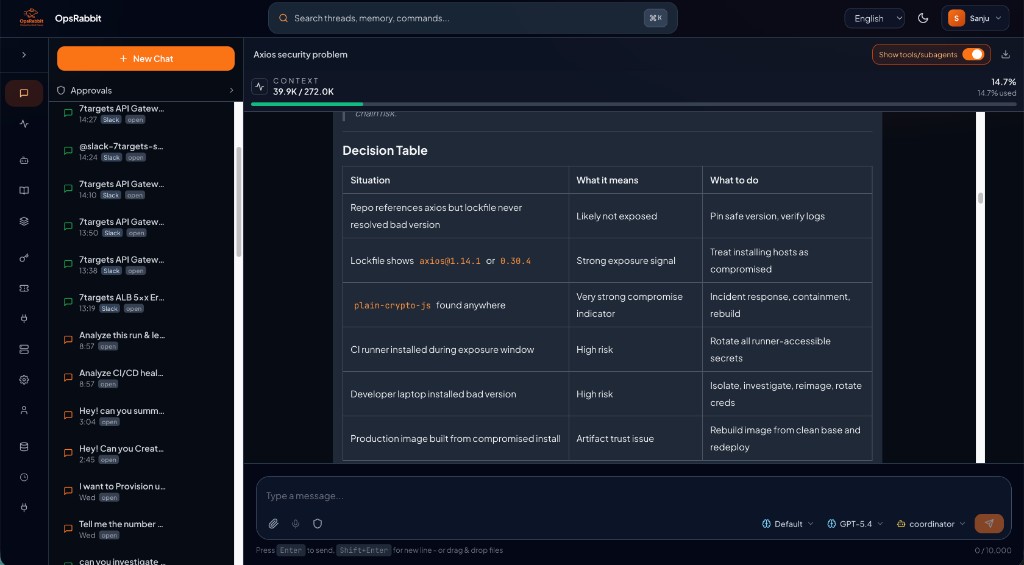
AI Incident Response in Action: Investigating a Cloud Supply Chain Attack on AWS
A real-world AI-driven investigation into the axios supply chain vulnerability on AWS, showing how OpsRabbit validates exposure using telemetry, runtime inspection, and intelligent reasoning.

From Intent to Infrastructure in Minutes: How OpsRabbit Deploys Secure Azure Environments Autonomously
See how OpsRabbit turns a simple request for two secure Azure VMs into a fully governed, production-ready environment in minutes — without tickets, manual templates, or fragile scripts.

Everyone Waits for Gaurav: Solving the Tribal Knowledge Bottleneck in IT Operations
Too many incidents depend on one engineer who 'just knows' what's going on. This post explores how tribal knowledge slows teams down and what scalable, AI-supported Ops can look like instead.

Why Ops Teams Can't Keep Up with AI Code
AI coding tools are accelerating development, but creating new challenges for operations teams. Discover how OpsRabbit helps bridge the gap between fast AI-generated code and stable production systems.
Latest Articles
31 articlesWhy Vulnerability Triage Breaks Down When Advisory Volume Surges
GitHub says vulnerability volume is hitting record levels, but the bigger operational problem is still context. Teams need faster answers about exposure, ownership, recent changes, and safe next actions before patching turns into progress.
AI Memory Poisoning Is Becoming an Ops Incident, Not Just a Personalization Feature
Persistent AI memory changes the response model: attackers can shape behavior over time, and responders need to trace what was stored, when it changed, and what workflows it can still influence before they can safely act.
What AIOps Means in Practice: Use Cases, Expectations, and Where OpsRabbit Fits
AIOps means different things to different teams: alert noise reduction, root cause analysis, self-healing, DevOps acceleration, service intelligence, and executive reliability. This guide maps those expectations to practical OpsRabbit workflows.
Why Kubernetes `nodes/proxy` Permissions Are More Dangerous Than They Look
Kubernetes v1.36 improves kubelet authorization, but many teams still carry broad `nodes/proxy` access into production. Here is why that matters for incident response and what to tighten now.
ChatGPT Google App Actions Are Now a Change-Management Issue for IT Ops
OpenAI's June 15, 2026 Google app-action rollout turns a connector update into a real change-management task for IT ops and Google Workspace admins.
ChatGPT's New Google App Actions Are an Ops Change, Not Just an App Update
Starting June 15, 2026, ChatGPT adds new Google Drive, BigQuery, and Google Meet-related actions that can require new OAuth scopes. For IT and security teams, that is an operational change window, not a routine feature toggle.
Why CI/CD Secret Theft Is Now an Incident Response Problem
Recent supply-chain incidents show that once build runners and workflow credentials are compromised, the problem lands on ops teams fast. The real challenge is assembling enough trusted context to contain the blast radius before it spreads.
AI Apps With Actions Are Becoming an Ops Incident Surface
Once AI apps can search internal systems, invoke tools, or act through MCP-connected services, they stop being just another productivity feature. They become part of the live incident surface.
Why AI Agent Permissions Sprawl Is Becoming an Ops Incident
Agent adoption is moving faster than visibility and least-privilege controls. Here is why MCP and A2A permissions sprawl is now an operations problem and what responders should do first.
Agentic AI Adoption Needs Operational Guardrails Before It Becomes an Ops Incident
CISA's new guidance on agentic AI adoption is a useful signal, but the real challenge for ops teams is building guardrails around access, ownership, telemetry, and response context before AI workflows create production incidents.
Why MCP-Connected Admin Tools Turn Fast Vulnerability News Into Ops Incidents
The nginx-ui MCP auth-bypass story is a good reminder that AI- and MCP-connected admin tools can turn a fresh disclosure into a live ops incident fast. The first bottleneck is usually not awareness. It is context.
Why Kubernetes AI Workloads Often Fail First at Memory Pressure, Not CPU
AI workloads in Kubernetes are famous for heavy compute demand, but many production incidents show up first as memory pressure, OOM kills, and evictions. Here is why that happens and how responders can debug it faster.
AI Investigation Context Windows Are Becoming an Ops Problem
AI copilots can help teams start incident investigations faster, but many still lose the thread once evidence spans alerts, logs, deploys, chat, and ownership data. That context-window gap is becoming an operations problem.
AI Alert Fatigue Is Now an AI Ops Incident, Not Just a Monitoring Problem
AI is not just creating more automation. It is making already noisy operational environments harder to interpret, which turns alert fatigue into a real incident-response problem.
Predictive Hardening for AI Ops Incidents: Why Faster Context Beats Blanket Lockdown
When an AI-connected incident starts moving, the winning move is rarely a blind lockdown. Teams need trusted context fast enough to apply temporary, targeted hardening before the blast radius grows.
How Kubernetes User Namespaces Change Production Debugging and Incident Response
Kubernetes user namespaces are now GA. Here is what that actually changes for platform teams, production debugging workflows, and incident response in real environments.
Why AI Runbooks Fail Without Live Infrastructure Context
AI-era runbooks do not usually fail because teams forgot a step. They fail because responders still need live ownership, change, access, and blast-radius context before they can act safely.
Kubernetes Image Volumes Give Platform Teams a Safer Debugging Pattern Than hostPath
Kubernetes image volumes give platform teams a cleaner, read-only way to deliver debugging artifacts into pods. That does not remove the need for access control, but it is a meaningful improvement over risky hostPath habits.
Indirect Prompt Injection Is Becoming an Ops Incident, Not Just an AI Security Footnote
Indirect prompt injection is no longer just a model-safety curiosity. For ops teams, it is becoming a real incident pattern where user-controlled data, retrieved content, or tool output can change agent behavior faster than responders can assemble context.
Shadow AI Is Creating Ops Incidents Faster Than Teams Can Build Context
AI adoption is moving faster than documentation, ownership, and guardrails. When something breaks, operations teams lose precious time figuring out which AI tools are involved, what changed, and what to do next.
Why Time-to-Context Is the Real Bottleneck in the Agentic SOC Era
The agentic SOC is becoming the new security operating model, but ops teams still lose time assembling service ownership, deploy history, runtime evidence, and next actions. Here is why time-to-context is the metric that matters now.
Agentic Runbooks for IT Operations: How to Cut Investigation Time Without Automating Blindly
Agentic runbooks help IT operations teams gather evidence, validate context, and recommend the next step faster, without turning incident response into a black-box automation gamble.
When MCP Endpoints Become an Ops Incident: What Teams Should Do After the nginx-ui Takeover Flaw
The nginx-ui takeover flaw is a good reminder that MCP and admin-plane integrations are now part of the incident surface. Here is how ops teams can scope exposure, check for config tampering, and respond faster with context.
The Agentic SOC Is Coming. The Operations Bottleneck Is Still Context.
The agentic SOC is quickly becoming the new security operating model, but production incidents still stall when responders cannot assemble service context fast enough. Here is where operations teams still get stuck, and why that gap matters.
Mitigating the Axios npm Supply Chain Compromise Before It Becomes a 2 A.M. Incident
The Axios npm supply chain compromise is a sharp reminder that dependency incidents become operations incidents fast. Here is how teams can investigate impact, reduce time-to-context, and respond with less chaos.
Why AI-Generated Code Is Creating a New Incident Response Problem
AI coding tools are speeding up software delivery, but they are also creating a new investigation burden for operations teams. The real problem is not just more change, it is slower time-to-context when production breaks.
MTTD, MTTF, MTBF, and MTTR: How OpsRabbit Improves the Metrics That Matter for DevOps
A practical guide to four core reliability metrics—and how AI-driven incident investigation with OpsRabbit helps teams detect faster, resolve sooner, and build a clearer picture of system health.
AI Incident Response in Action: Investigating a Cloud Supply Chain Attack on AWS
A real-world AI-driven investigation into the axios supply chain vulnerability on AWS, showing how OpsRabbit validates exposure using telemetry, runtime inspection, and intelligent reasoning.
From Intent to Infrastructure in Minutes: How OpsRabbit Deploys Secure Azure Environments Autonomously
See how OpsRabbit turns a simple request for two secure Azure VMs into a fully governed, production-ready environment in minutes — without tickets, manual templates, or fragile scripts.
Everyone Waits for Gaurav: Solving the Tribal Knowledge Bottleneck in IT Operations
Too many incidents depend on one engineer who 'just knows' what's going on. This post explores how tribal knowledge slows teams down and what scalable, AI-supported Ops can look like instead.
Why Ops Teams Can't Keep Up with AI Code
AI coding tools are accelerating development, but creating new challenges for operations teams. Discover how OpsRabbit helps bridge the gap between fast AI-generated code and stable production systems.
Ready to Transform Your Operations?
Ask for a demo today. Experience how OpsRabbit can reduce your MTTR by up to 90%.