
Quick answer: Tribal knowledge concentrates incident response in a few people, which increases MTTR and burnout; scalable ops requires shared context and repeatable investigation workflows.
When Incident Response Depends on One Person
How Teams Can Scale What Their Best Engineers Know
Too many incidents depend on one engineer who "just knows" what's going on. This post explores how tribal knowledge slows teams down; and what scalable, AI-supported Ops can look like instead.
What Is Tribal Knowledge in IT Ops and Why Does It Matter?
At 2:43 AM, a critical alert goes off.
Logs flood in.
Slack lights up.
PagerDuty escalates.
Everyone in the team is watching the same dashboards — but nobody takes action.
They're all waiting for Gaurav.
(Name changed for anonymity.)
Why? Because he's the only one who remembers the workaround from six months ago.
He knows that this alert is often a false positive unless tied to a config drift.
He understands the system well enough to know what's noise and what's real.
That's tribal knowledge — and it's one of the most common, yet overlooked bottlenecks in IT Operations.
How Tribal Knowledge Creates Bottlenecks and Burnout
What's wrong with relying on a few senior engineers?
When operational knowledge lives inside the heads of just one or two team members, resolution times slow down.
Escalations increase.
And team morale suffers.
This pattern shows up in nearly every DevOps or SRE team:
- Everyone defers to one person for production issues
- New engineers don't have enough context to act confidently
- Documentation is outdated or missing entirely
- Escalation happens too late because people hesitate to act
What's the Risk of Not Solving This?
You're not just facing slower fixes.
You're facing structural risk.
Operational Impact of Tribal Knowledge Bottlenecks
- Increased MTTR (Mean Time to Resolve) across all incidents
- Missed SLAs and uptime goals
- Team over-dependence on seniors, causing burnout
- Delayed escalations and unclear accountability
- Organizational memory loss when someone leaves
Tribal Knowledge Gaps Undermine IT Operations
- Increased MTTR - Incidents take longer to resolve.
- Missed SLAs - Uptime goals are not met.
- Team Over-Dependence - Seniors experience burnout due to reliance.
- Delayed Escalations - Accountability is unclear, causing delays.
- Organizational Memory Loss - Knowledge is lost when employees leave.
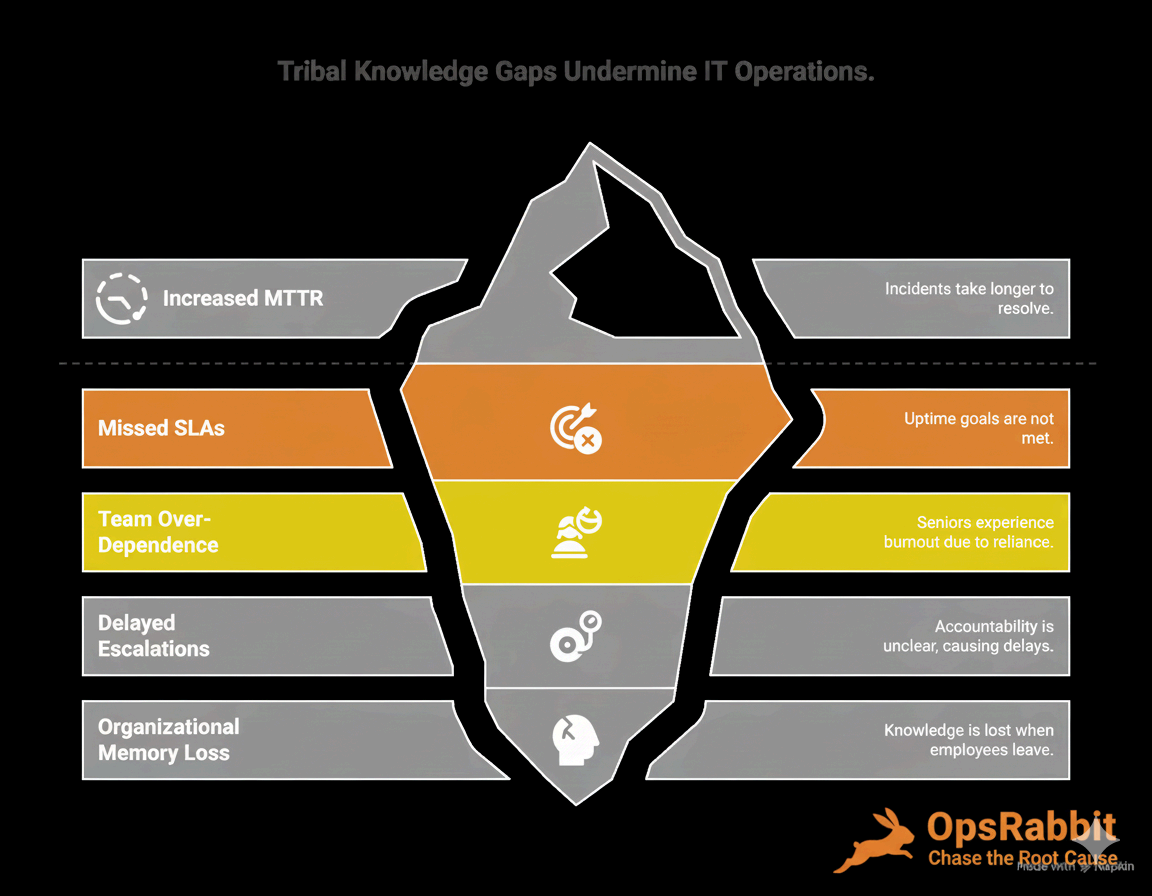
Fig: Moving from heroic to scalable operations
Tribal knowledge gaps grow faster than teams can document — especially when AI copilots are accelerating code pushes and infrastructure complexity.
How Can Ops Teams Scale Knowledge Without Burnout?
There's no single tool or process that solves this overnight.
But forward-thinking teams are making a shift:
They're moving from heroic Ops to scalable Ops.
What does a scalable incident response look like?
- Capturing real-time investigation steps, automatically
- Making them searchable, explainable, and actionable
- Using AI tools to recognize recurring patterns and suggest relevant next steps
- Supporting junior engineers with context-rich guidance
- Turning every resolved issue into reusable organizational knowledge
One Way We've Seen This Work: OpsRabbit
At Applied AI Consulting, we've worked with many teams who faced this exact problem.
That's why we created OpsRabbit, not to replace senior engineers like Gaurav, but to learn from what they know and help the rest of the team benefit from it.
How OpsRabbit Helps Reduce Bottlenecks
- Investigates incidents by analyzing logs, configs, metrics, and recent commits
- Matches incidents with similar past cases, even without formal runbooks
- Explains recommendations with supporting evidence, not just suggestions
- Learns from every incident and makes that knowledge available the next time
- Integrates with existing tools like Zabbix, Slack, and Jira
Incident Investigation and Resolution
| Feature | Description |
|---|---|
| Incident Investigation | Analyzing logs, configs, metrics, and commits to investigate incidents |
| Matches Past Cases | Matches incidents with similar past cases, even without formal runbooks |
| Explains Recommendations | Explains recommendations with supporting evidence, not just suggestions |
| Learns From Incidents | Learns from every incident and makes knowledge available for the future |
| Integrates With Tools | Integrates with existing tools like Zabbix, Slack, and Jira |
Final Thought: What Happens When Gaurav Isn't Online?
The next time a critical alert hits your systems, and your team waits for someone like Gaurav to log in and make sense of it, ask yourself:
What if your systems could learn from him and help everyone else move faster next time?
That's not just automation. That's resilience.
And it's the kind of shift that transforms firefighting teams into high-performing ones.
Frequently Asked Questions
Q: What is tribal knowledge in IT operations?
A: Tribal knowledge refers to undocumented experience and system behavior known only by a few senior engineers, creating bottlenecks during incidents.
Q: How can DevOps teams scale tribal knowledge?
A: By capturing real-time investigation steps, making them searchable, and using AI tools like OpsRabbit to surface past learnings during future incidents.
🚀 Ready to scale what your best engineers know? Join our pilot program and see how OpsRabbit can help your team move from heroic to scalable operations.
Ready to Transform Your Operations?
Ask for a demo today. Experience how OpsRabbit can reduce your MTTR by up to 90%.