
Quick answer: AI coding tools are speeding up software delivery, but they are also creating a new investigation burden for operations teams. The real problem is slower time-to-context when production breaks.
AI coding tools are changing how software gets built.
That part is obvious now.
Teams are shipping faster. Smaller teams can take on more. Features move from idea to production with a lot less friction than they used to.
That is good news for product velocity.
It is not automatically good news for the people who have to make sense of production when something breaks.
That is the part people skip over.
Because once the code is live, the question is no longer, “How fast did we build this?”
It becomes, “Can we figure out what is happening quickly enough to fix it?”
And that is where a new incident response problem starts to show up.
This is not really a story about speed
Most of the conversation around AI-assisted development is about productivity.
Can engineers move faster? Can smaller teams ship more? Can copilots reduce repetitive work?
Sure, all of that matters.
But production systems do not care how the code was written. They care whether the system behaves predictably under load, across dependencies, under weird runtime conditions, and in the middle of the messy reality every ops team already knows too well.
When incidents happen, most teams do not suffer from a lack of alerts.
They suffer from a lack of usable context.
They need to know things like:
- what changed
- which dependency matters
- which service is actually failing
- whether this is new or familiar
- what evidence points to the most likely root cause
That work is still manual in far too many environments.
AI-generated code makes the investigation gap more obvious
This is not an anti-AI argument.
The issue is not that AI-generated code is inherently reckless or broken.
The issue is simpler than that.
AI-assisted development increases the pace of change. Meanwhile, operational understanding is still spread across dashboards, logs, traces, diffs, tickets, and the memory of whoever happens to be awake.
That combination gets expensive during incidents.
1. More change reaches production without shared context
A developer may understand the prompt, the implementation shortcut, or the local decision that produced the code.
But once that change is deployed, the operations team still has to reconstruct what happened from scattered evidence.
If the alert fires and nobody can quickly connect the dots between deploys, dependencies, runtime behavior, and prior incidents, the real work has barely started.
2. Hidden dependencies hurt more when time matters
A lot of incidents are not caused by one giant, obvious mistake.
They come from interaction effects.
A version bump here. A rollout there. A permission assumption nobody noticed. A side effect in a service boundary. A runtime edge case that looked harmless in review.
Those problems are survivable when teams can gather context quickly.
They become expensive when responders are forced to piece everything together by hand.
3. Ops inherits the ambiguity
Coding copilots help during development.
They do not jump into the incident channel at 2:17 AM and explain why one rollout degraded another service, why the alert pattern looks half-familiar, or which recent change is actually worth investigating first.
That burden lands on SRE, DevOps, CloudOps, and IT operations teams.
And it lands there fast.
The real bottleneck is time-to-context
A lot of incident tooling is built around detection.
That makes sense. You need to know something is wrong.
But many teams already have plenty of signal. In fact, they have too much of it.
The harder part begins after the alert.
That is when responders need quick answers to questions like:
- Was there a recent deploy?
- Which services or dependencies changed?
- Are related errors showing up elsewhere?
- Has this happened before?
- What evidence points toward the highest-probability root cause?
That is where time disappears.
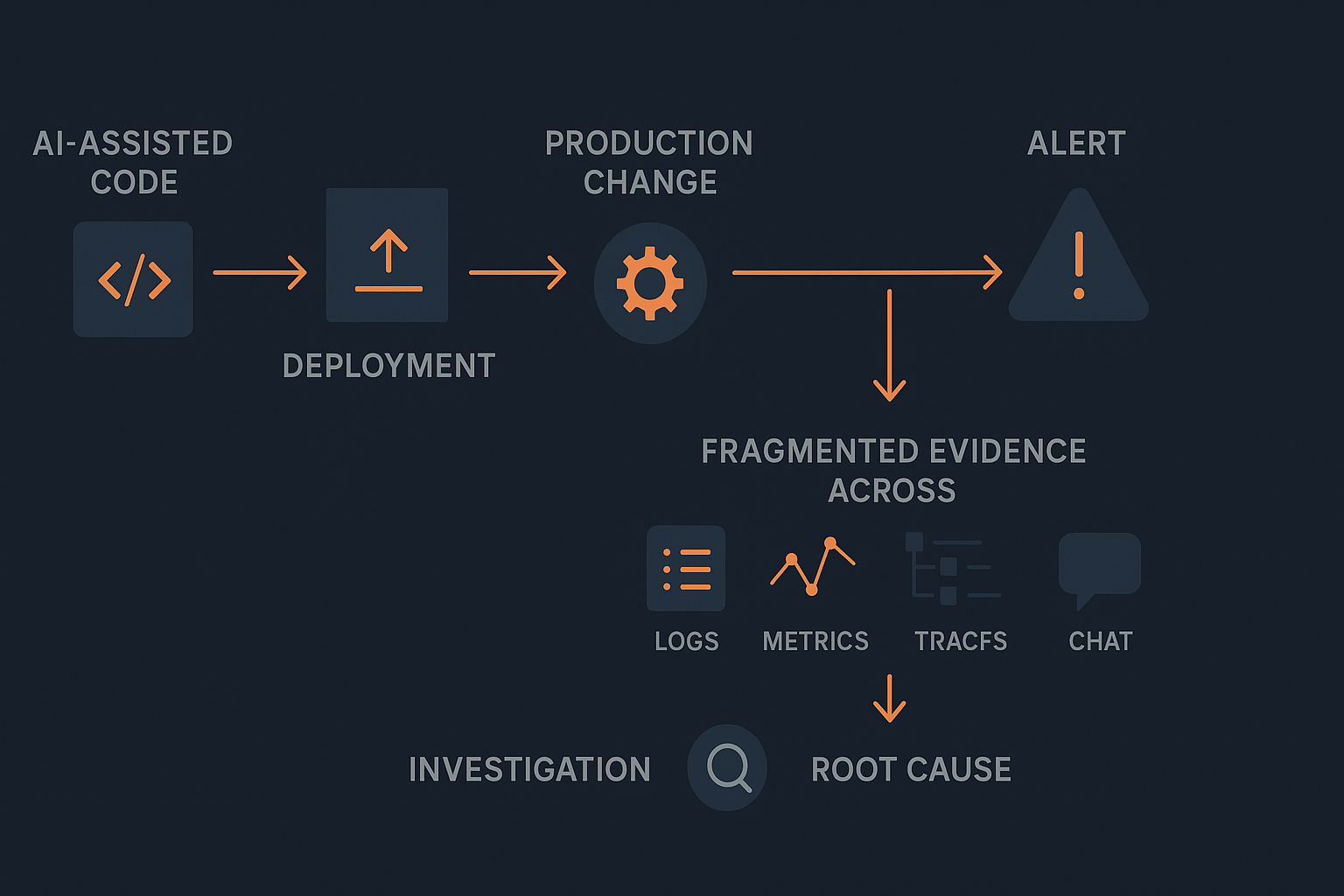
The real delay often starts after the alert, when teams need context from too many systems.
Why more dashboards do not fix this
Most teams are not short on tools.
They already have observability platforms, cloud consoles, incident channels, issue trackers, and some graveyard of old runbooks sitting somewhere in the background.
The problem is not missing data.
The problem is turning all that data into an evidence-backed story about what is happening right now.
That means:
- correlating signals across tools
- deciding which signals matter
- ruling out bad leads
- connecting the alert to recent changes
- surfacing the next useful action quickly enough to matter
That is investigation work. And it is where a lot of teams still lose most of their time.
What better incident response looks like
A better workflow starts with a different assumption.
Instead of asking responders to assemble context from scratch every time, the system should help build that context as soon as the incident begins.
In practice, that looks more like this:
- An alert arrives.
- Recent changes, dependencies, and service relationships are gathered immediately.
- Logs, metrics, traces, and other operational signals are correlated.
- Similar past incidents or known patterns are surfaced.
- A working incident narrative appears with evidence attached.
- The responder decides what to verify, escalate, or remediate next.
That does not remove humans from incident response.
It removes a lot of the repetitive digging that slows them down before they can do the useful part.
Where OpsRabbit fits
This is the gap OpsRabbit is built for.
Coding copilots help teams produce software.
OpsRabbit helps operations teams understand what is happening when that software meets production reality.
The goal is not just to say that something failed.
The goal is to help answer:
- what likely changed
- what evidence matters most
- what systems are involved
- what the incident most likely means
- what the responder should look at next
That is a different job than monitoring.
And it is a different job than code generation.
It is incident investigation support.
Final thought
AI-assisted development is not slowing down.
So the real operational question is not whether teams will ship faster.
They will.
The better question is whether incident response will keep up.
If your team is still spending too much time turning alerts into context, that is probably the gap worth fixing first.
And if that sounds painfully familiar, OpsRabbit may be worth piloting.
Ready to Transform Your Operations?
Ask for a demo today. Experience how OpsRabbit can reduce your MTTR by up to 90%.